개인프로젝트때 스프링 배치를 사용했다. 근데 사실 자신감이 없다. 이부분에 대해서는 스프링 배치를 사용해보고 싶어서 , 필요해서 사용한거긴하지만 코드에는 자신이 없었다.. 근데 이걸 멘토님이 보고 알아채셨다.. 혹시 여기 자신없죠? 라고 하셨다... 역시 현업개발자분들의 눈은 못 속이는 군..ㅎㅎㅎ 그래서 정리하는 스프링 배치!
배치란?
배치란 간단하게 일관처리라는 의미이다. 데이터를 실시간으로 처리하는 것이 아니라 일괄적으로 처리하는 작업이다.
근데 왜?? 실시간으로 처리하지 않고 일괄적으로 처리할까??
예를 들어보자. 대부분의 커머스 사이트에서는 매일 전날의 데이터를 집계한다. 이 집계과정을 어디서 수행해야할까?
1. 매번 검색할때마다 집계를 수행해야할까?
-> 그건 좀.. 데이터가 5십만개에서 1억개이상 있을 텐데 매번 집게 매출을 볼때마다 실행된다면 너무 리소스 낭비 + 서버에 부담이 간다.
뿐만 아니라 어처피 전날 집계는 하루가 지나기 전까지 동일하다. 그렇다면 한번만 실행하고 해당 하루동안에는 처리된 데이터를 보여주면 되지 않을까?
2. 스프링 배치말고 단순히 스케줄러 통해서 하면 안되나?
-> 그것도 좀.. 그 이유는 스프링 배치의 기능에 존재한다.
스케줄러로만 데이터를 조회해서 실행하다고 가정해보자. 근데 만약 중간에 에러가 발생했다..
여기서 문제.. 어느 데이터서부터 스탑된것일까?? 지금까지 반영된 데이터는 어디까지이지??
어디서부터 잘못된지 모른다면 다시 처음부터 시작해야해?? 중간의 에러하나로 인해 다시 처음부터 시작해야하는 상황이 발생할 수 도 있다.
그러나 스프링 배치의 경우 어디서 잘못되었는지, 무엇 때문인지 추적가능하다.
3. 그래 일단 스케줄러 사용한다고 해! 그럼 비즈니스 로직 외에 부가적인 실패처리등 이런거 어케 할껀데?
-> 이부분도 스프링 배치가 해준다. 물론 스케줄러 이용해서 코드 짜서 할 수 있지만... 스프링 배치가 실패의 경우에 대한 기능을 지원해준다. 그럼 이미 존재하는 기술을 사용하는게 더 낫지 않은가??
어째든 스프링 배치는 한마디로 말하자면 개발자의 편의성을 도와준 기술스택이다
스프링 배치의 장점을 정리하자면
1. 대용량 데이터 처리 가능
2. 실패시 트랜젝션을 통해 롤백할 수 있고 실패한 부분에 대해서 추적가능하다
3. 실패의 경우 재시도할 수 있는 기능도 지원한다(부가적인 기능 지원)
스프링 배치는 언제 사용되는가?
아주 간단하게는 앞서 얘기한 일매출 집계, 데이터 백업, 구독자에게 정기적으로 메일을 보내야할때등 과 같을때 사용된다.
스프링 배치 용어 살펴보기
영어를 매우 못하지만..ㅎㅎ spring batch docs와 여러 블로그를 참고해서 정리해볼것이다.

1. Job
- 스프링 배치 계층에서 가장 상위이다
- jon은 step인스턴스들의 컨테이너이다
- steps을 포함하고 있고 재시작성에 대한 스텝들도 포함하고 있다
- job이름, step정의 및 순서, job을 재시작할 건지
쉽게 말해서 job은 steps들의 박스들이다. 예를 들어 A라는 배치 기능에 b,c,d,f라는 단계들이 필요하다고 하자. 이때의 b,c,d,f 스텝이고 이를 하나로 A라는 job이라고 할 수 있는 것이다. 거기서 b,c,d,f의 실행 순서를 정할 수 있고 만약 step이 실패하여 job의 재시작 유무와 같이 실패처리에 대해서 로직을 작성할 수 있다.
2. JobInstance
- 특정 job의 실제 실행 인스턴스이다
- 같은 jobInstance를 사용하면 이전 실행 상태에 따라 실행여부가 정해집니다.
- 새로운 jobInstance는 새롭게 시작한다의 의미이고 이미 존재하는 jobInstance는 남은 것부터 시작한다의 의미다
쉽게 말해 jobInstance는 job을 실행시켜주는 인스턴스다.
jobInstance는 실패할 경우 다시 실행하여 작업을 완료할 수 있다. 그래서 영어로 해석한 거와 같이 기존 인스턴스를 사용하면 상태값을 보고 중단된 작업을 다시 시작할지 결정할 수 있고 새로운 인스턴스는 진짜 처음부터 시작하는 것이다.
3. JobParameter
- JobParameter를 통해 jobInstance를 구별한다
- JobInstance = Job + JobParameter
즉 jobParameter는 jobInstance를 구별하는데 사용된다. Job이 실행될때 필요한 파리미터를 제공하기도 하지만 JobInstance구별하는 역할도 한다.
4. JobExecution
- Job을 한번 실행한 시도이다. JobInstance가 실패했든 성공했든 실행될때마다 새로운 jobExecution이 생긴다
- Job과 JobInstance는 실행해야하는 것에 대한 기본 설정이라면 JobExecution은 중요 매커니즘이고 여러 설정들을 포함하고 있다
JobInstance 한번 시행에 하나의 JobExecution이 생긴다. 다시말해 JobInstance가 실패했을때 재시도하면 같은 JobInstanc 가 실행되지만 새로운 JobExecution이 생긴다.
JobExecution의 경우 성공 or 실패 상태, 시작시간, 끝난 시간, 마지막 updated시간 등과 같은 값들을 포함하고 있다.
예를 들어

JobInstance + JobParameter가 실행되면 JobExecution이 저렇게 생긴다.(칼럼들은 더 다양한데 간단한 설명들을 위해 생략하였다)
보면 1의 JobInstance 하나인데 실패한 JobExecution과 이후 다시 실행하여 성공한 JobExecution을 볼 수 있다.
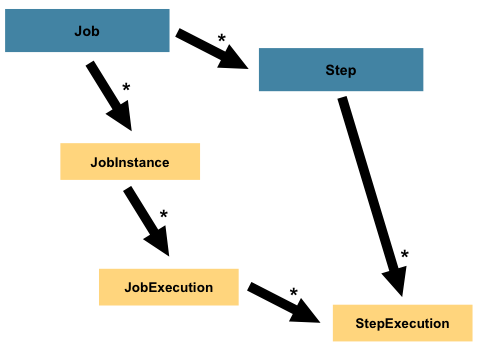
1. Step
- Job 하위 단계로서 실제 배치 처리 작업이 이루어지는 단위
- 한개이상의 step으로 job이 구성되고 각 step은 순차적으로 처리된다.
2. StepExecution
- Step의 한번 실행을 나타낸다. Step의 실행상태, 실행 시간등의 정보를 포함한다.
- JobExecution과 비슷하게 각 step의 실행시도마다새로운 StepExecution이 생성된다
3. ExecutionContext
- key/value 형태의 데이터 저장소이다.
- StepExecution과 JobExecution 간의 데이터를 공유할때 사용된다
- Job이나 Step이 실패했을때, ExecutionContext를 통해 마지막 실행 상태를 재구성하여 재시도 또는 복구 작업이 가능하다
4. JobRepository
- 배치 관련 모든 정보를 저장하고 관리하는 메커니즘
- Job 실행정보(JobExecution), Step 실행정보(StepExecution), Job 파라미터(JobParameters)등을 저장하고 관리
- Job이 실행될 때, JobRepository는 새로운 JobExecution과 StepExecution을 생성하고, 이를 통해 실행 상태를 추적합
5. JobLauncher
- Job과 JobParameters를 받아 Job을 실행하는 역할을 함
- JobRepository를 통해 Job을 실행함
1. Tasklet
- 간단한 단일 작업을 할때 사용된다.
- 일반적으로 ItemReader, ItemProcessor, ItemWriter를 수행하는데 간단한 작업일 경우 tasklet으로 처리
2. ItemReader
- 배치 작업에서 처리할 아이템을 읽어옴
- 데이터베이스, 파일 등 데이터를 읽어오는 다양한 구현체들이 있음
3. ItemWriter
- 데이터를 최종적으로 기록하는 역할
- 데이터베이스, 파일생성 등 다양한 방식으로 데이터를 기록
4. ItemProcessor
- ItemReader로부터 읽어온 아이템을 처리하는 역할
- 선택적인 부분이라 필요에 따라 사용 -> 필터링, 변환 등의 작업을 수행할 수 있음
이번시간은 간단하게 개념을 알아보았다. 다음 블로그에서는 코드로 어떻게 사용하는지 알아볼 예쩡!
https://velog.io/@clevekim/Spring-Batch%EB%9E%80-%EB%AC%B4%EC%97%87%EC%9D%B8%EA%B0%80
'개발 이론 > Spring Batch' 카테고리의 다른 글
| [Spring Batch] 예제만들어보기 (0) | 2024.02.29 |
|---|
