Elastic Search 프로젝트에 적용하기
하하 안녕하슈 오랜만에 블로그를 쓰네요... 요즘 개인프로젝트 하느라 바빠서 써야할 블로그들이 산더미인데 빠르게 완료해야하는 프로젝트라 미루고미루다가 아주 조금 널널해져서 적어보아유.
현재 개인프로젝트에서 예약서비스를 구현하고 있다. 그래서 현재위치, 이름 기준으로 검색을 해야하는 기능이 필요하다. 이 기능을 구현하기 위해 elastic search를 이용했다.
사실 적용하는 방법은 구글에 치면 너무 많다. 궁금한건 왜 elastic search를 이용하나..? 가 궁금하다.
알아보기전에 색인과 역색인에 대해서 알아보자
색인과 역색인
색인
키워드를 찾아보기 쉽도록 정렬/나열한 목록을 말한다
예를 들어 책을 보면 목차가 보일것이다. 그것이 바로 색인이다.
역색인
키워드를 통해 문서를 찾아내는 방식이다.
예를 들어 책 맨뒤에 보면 해당 글자가 어디나오는지 표시되는 페이지가 있을 것이다. 그것이 역색인이다.
여기서 문제!!!
색인 검색이 빠르까?? 역색인 검색이 빠를까??
검색성능은 역색인이 빠르다. 그 이유는 "특정"키워드가 포함된 문서를 찾아내기 때문이다.
예를 들어 색인을 통해 검색한다면 like "%hello"를 통해서 검색한다. 이는 위에서부터 row의 모든 내용을 읽어야하기 때문에 기본적으로 데이터의 양이 많아질수록 검색 속도가 느려질 수 밖에 없다.
반면 역색인는 "hello"가 들어간 문서 id를 바로 얻을 수 있다.(pk,물리적 주소)
데이터가 늘어나도 찾아야하는 행이 늘어나는 것보다는 해당 "hello"가 들어간 id 배열 값이 추가되는 것이다.
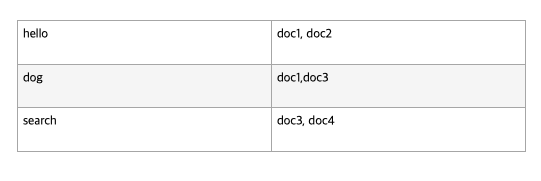
오케 어느정도 역색인, 색인 이해됬어. 그래서 왜 elastic search가 검색속도가 빠른데??
elastic search도 역색인을 이용하기 때문이다.
예를 들어 "dalbeen"이라는 단어를 검색했을때 어느 책에 10쪽,60쪽,500쪽에 나온다고 가정해보자
rdbms의 경우 500번째 행까지 탐색하지만 역인덱스 구조의 경우 "dalbeen"라는 키워드(term이라함)가 가르키는 도큐먼트가 무엇인지만 확인하면 된다.
근데 만약에 문장이라면...?
예를 들어보자. "The dog likes me"라는 문장이 있다고 가졍해보자
일단 띄어쓰기로 분리한다. "The, dog, likes, me"로 분리된다. 이렇게 문장을 특정 단위로 분리하는 것을 토크나이징이라고 하며 분리된 단어를 토큰이라 한다.
이후 대문자를 모두 소문자로 변경하고 토큰을 ascii순서로 정렬한다.
-> a, an,the,to와 같은 검색에 의미가 없는 불용어를 제거한다.
-> 형태소 분석과정을 거쳐 단어를 원형을 변환한다. 예를들어 likes를 like 변경한다. (한글의 경우 elastic seach는 nori를 통해 형태소 분석을 한다)
마지막으로 중복된 토큰은 병합하고, 동의어 처리한다.
위 과정에서 처리하는 작업이 좀 걸릴것같다. 특히 한글의 경우 형태소 분석에 더 많은 시간이 걸린다. 이 걸린 시간을 NRT(near real-time)이라고 한다.
오호 그렇군... 그럼 단점은 없어??
일단 앞서 말했듯이 처리과정에 시간이 조금 걸린다는 점??
그리고 데이터의 업데이트를 지원하지 않고 기존 문서를 삭제하고 다시 생성하는 방식을 취한다. 또한 트랜젝션이나 롤백을 지원하지 않는다.
근데...Mysql fulltext 랑은 뭔차이점이야??
일단 Mysql fulltext도 긴문자의 텍스트 데이터를 키워드로 쪼개서?? 검색하잖아.
찾아보니 다 영어로 되어있었지만...우리에게는 번역기가 있지 않은가..?
MySQL:항상 데이터를 인덱싱하고 검색할 수 있습니다.간단하게 설정할 수 있고, 빠른 검색이 가능합니다.그러나 특정한 검색 기능이나 성능 면에서 ElasticSearch보다는 제한적일 수 있습니다.
ElasticSearch:데이터를 하나의 단위로 묶어서 색인화할 수 있습니다. 예를 들어, 모든 콘텐츠, 댓글, 태그를 하나로 묶어서 검색할 수 있습니다.MySQL보다 더 유연하며, 성능과 결과에서 더 좋은 퍼포먼스를 제공할 수 있습니다.그러나 추가적인 스택을 관리해야 하고, 데이터를 업데이트하거나 색인화하는 것을 직접 관리해야 합니다
음.. 그러니까 mysql full text의 경우 열을 지정에서 어떤 풀텍스트인덱스를 생성할 것인지 지정해야하지만 elastic search는 조금더 유연하게 가능한 것같다.
뿐만 아니라 정말 많은 다량의 데이터라면 elastic seach가 유리하다. 그 이유는 elasticsearch는 미리 정리된 데이터를 검색하는 반면 mysql에서는 실제 데이터베이스에 질의하여 검색결과를 가져오는 것이다. 그니까 쉽게 말해 elastic search는 검색을 위한 쿼리를 사용하지만 미리 색인된 데이터를 기반으로 검색하므로 데이터베이스에 직접적으로 sql쿼리를 날리는 것과는 차이가 있다고 한다.
또 생각하자면 elastic search의 경우 형태소 분석을 통해 동의어 처리, 다양한 텍스트 처리 옵션을 제공하지만 mysql full text의 경우 단어 단위로 인덱싱하고 검색할뿐 동의어나 기본형태 변화을 고려하지 않는다
https://stackoverflow.com/questions/41892179/elastic-search-full-text-vs-mysql-full-text
https://hudi.blog/elasticsearch-inverted-index/