[개인프로젝트] ElasitcSearch 에 대해 좀 더 공부해보자 (1)
개인프로젝트에서 ElasitcSearch를 사용했다. 생각해보면 개념을 정확하게 인지하지 않은채 적용한 거같아서 좀더 공부해보았다.

ElasticSearch
루씬 기반의 오픈소스 검색엔진이라고 한다.
ElasticSearch의 특징은
1. 준실시간 검색 시스템 : 실시간이라 생각될 만큼 색인된 데이터가 빠르게 검색된다.
2. 고가용성을 위한 클러스터 구성 : 한대 이상의 노드로 클러스터를 구성하여 높은 수준의 안정성 달성 및 부하 분산 가능
3. 동적 스키마 생성 : 입력될 데이터들에 대해 미리 스키마를 생성하지 않아도 동적으로 생성가능
4. Rest API 기반의 인터페이스 : Rest API 기반의 인터페이스를 제공하여 비교적 사용을 위한 진입 장벽이 낮다
클러스터와 노드
컴퓨터에서의 클러스터란 여러대의 컴퓨터들이 연결되어 하나의 시스템처럼 동작하는 컴퓨터들의 집합을말한다
ElasticSearch 또한 여러대의 노드들이 각자의 역할을 바탕으로 연결되어 하나의 시스템처럼 동작하는 것을 클러스터라고 한다.
그래서 앞서 말한 고가용성을 위한 클러스터를 위해 노드를 늘려서 성능을 높일 수 있다. (다만 노드를 늘린다고 무조건 성능이 높아진다는 것은 아니다)
1. 노드의 종류
- 마스터 노드 : 클러스터 상태 관리 및 메타데이터 관리
- 데이터 노드 : 문서 색인 및 검색 요청 처리
- 코디네이팅 노드 : 검색 요청 처리
- 인제스트 노드 : 색인되는 문서의 데이터 전처리 (ex) 특정 필드에 특정 값을 수정한 후 넣는 것)
물론 노드들의 각자의 역할이 존재하지만 어떤 노드에 어떤 요청을 해도 동일한 응답을 준다.

즉 마스터 노드에 데이터를 요청해도 마스터 노드가 데이터노드한테 해당 데이터값을 받고클라이언트에게 반환해준다.
다만 이는 불필요한 경로들이 존재한다. 그래서 각 노드가 본인의 역할에 충실하도록 구성하는 것이 중요하다.
(로드밸런서를 통해 접근에 차단을 할 수 있다고 한다)
인덱스

인덱스란 문서가 저장되는 논리적 공간이다. 문서를 저장하기 위해서는 반드시 인덱스가 존재해야한다.
인덱스를 설계하는 것이 ElasticSearch 사용의 첫단계이다.
인덱스를 설계할때는 상황에 따라 다르지만 모든것을 아우르기 vs 각 자료별 나누기를 고려할 수 있다.
예를 들어 자동차라는 것으로 자료를 아우를 수 있지만, 소형차/대형차/중형차 로 각 차 유형별 인덱스를 따로 만들어 저장할 수 있다.
위와 같은 인덱스 설계에 따라 문서의 구조라든지 검색쿼리가 달라진다.
예를 들어 자동차라는 인덱스가 존재한다면 필드에 "type"을 통해 소형/대형/중형을 구분해야한다.
그러나 인덱스를 나누어 소형차한테 값을 저장할때는 "type"이라는 필드를 빼고 저장가능하다.
인덱스를 하나로 하든 여러개로 하든 둘다 장단점이 존재한다.
인덱스 하나
- 관리해야하는 인덱스 수가 적어 리소스가 적게 발생한다.
- 다만 쿼리와 문서의 구조가 복잡해질 수 있다.
인덱스 여러개 나누기
- 각각의 경우에 최적화된 쿼리와 문서구조를 사용할 수 있다
- 다만 관리해야하는 인덱스의 수가 많아 관리 리소스가 발생할 수 있다
샤드
인덱스에 색인된 문서가 저장되는 공간이다 (하나의 인덱스는 반드시 하나 이상의 샤드를 가진다)
노드안에 샤드가 존재한다.
1. 샤드의 종류
- 프라이머리 샤드 : 문서가 저장되는 원본 샤드, 색인과 검색 성능에 모두 영향을 줌
- 레플리카 샤드 : 프라이머리 샤드의 복제 샤드 ,검색성능에 영향을 줌, 프라이머리 샤드에 문제가 생기면 레플리카 샤드가 프라이머리 샤드로 승격
2. 샤드의 설정
PUT /member/_settings
{
"index" : {
"number_of_shards" : 3,
"number_of_replicas" : 1
}
}
프라이머리 샤드는 3개이고, 프라이머리 샤드당 레플리카 샤드가 1개식 생기는 것이므로 총 샤드의 개수는 6개로 설정한것이라 할 수 있다.
3. 샤드 라우팅
기본적으로 프라이머리 샤드가 3개 있다고 하자. 이는 내부 규칙에 의해 1->2->3으로 저장된다고 했을때
만약 샤드의 개수를 추가한다면 문서 저장규칙이 바뀌게 되어 프라이머리 샤드는 만들고나서 변경이 불가능하다
기본적으로 number_of_shards는 기본 1이니 상황에 따라 샤드를 추가하고 사용하자
다만 매번 인덱스를 생성할때마다 샤드관련 설정이 귀찮다면 인덱스 템플릿을 사용하자
PUT _index_template/base_template
{
"index_patterns" : ["hello-*"],
"template" : {
"settings": {
"number_of_shards" : 3,
"number_of_replicas" :2
}
}
}이렇게 하면 hello- 로 시작하는 모든 인덱스에 프라이머리 샤드 3개, 레플리카 샤드 6개가 생성된다
4. 샤드의 배치
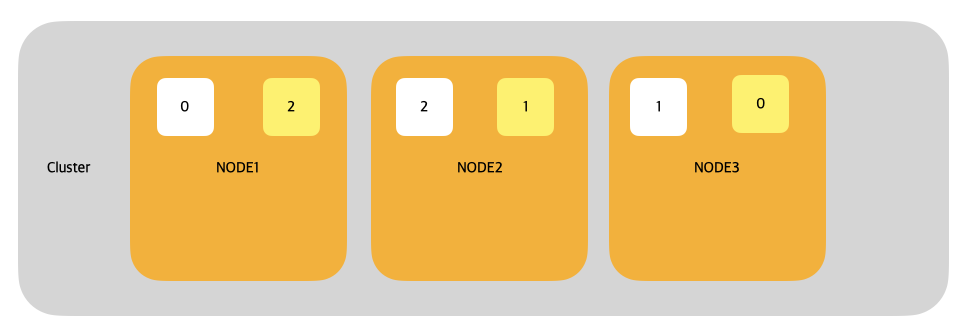
흰색 정사각형: 프라미머리 샤드
노란색 정사각형 : 레프리카 샤드
기본적으로 하나의 노드에 같은 프라이머리샤드와 레플리카 샤드를 넣지 않는다. 그 이유는 만약 Node2가 다운됬을때 2,1샤드가 유실되게 되는데 이때 다른 노드에 남아있는 2,1 샤드가 데이터 유실없이 사용가능하게 하기 때문이다.
만약 프라이머리 샤드가 유실되었다면 남아있는 레플리카 샤드가 프라이머리 샤드로 승격되고 유실된 만큼의 샤드가 새로 생성된다.
mapping
위의 이미지에서 봤듯이 mapping은 schema느낌이다.
즉 문서의 구조를 나타내는 정보이다. 앞서 ElasticSearch가 스키마리스라고 했지만 미리 정의하지 않아도 괜찮다라는 의미이다.
1. 매핑의 종료
- 동적 매핑 : 처음 색인되는 문서를 바탕으로 매핑정보를 ElasitcSearch가 동적으로 생성
- 말그대로 처음 색인되는 문서는 자동으로 매핑정보를 생성한다
- 다만 생성된 후에는 타입이 안맞게 문서가 들어오면 파싱에러가 발생한다
- 정적 매핑 : 문서의 매핑정보를 미리 정의
- 문서 필드들이 가지는 값에 따라 타입을 정의해둘 필요가 있거나 불필요한 색인이 발생하지 않게(문자열 필드 text vs keyword) 하기 위해 사용
https://victorydntmd.tistory.com/308
https://www.inflearn.com/course/elasticsearch-essential/dashboard