[Spring] 동시성 어떻게 해결할 것인가? - 분산락
개인프로젝트에서 예약시스템을 구축하고 있다. 그러다보니 동시성 문제가 매우 중요하다. 한날짜에 같이 예약을 걸게 되면 최악의 상황이...그래서 어떻게 동시성을 핸들링 할까하다가 나같은 경우 redisson의 분산락을 이용했다.
일단 동시성이 왜 일어나는지와 동시성을 해결할 수 있는 방법에 대해서 얘기해보자.
이 글은 redis를 통한 분산락 해결책을 더 자세하게 다룰 계획이다.
동시성??그게 뭐고 왜 일어나는 건데??
동일한 하나의 데이터가 2개이상의 스레드가 동시에 데이터를 제어또는 접근할때 발생하는 문제이다.
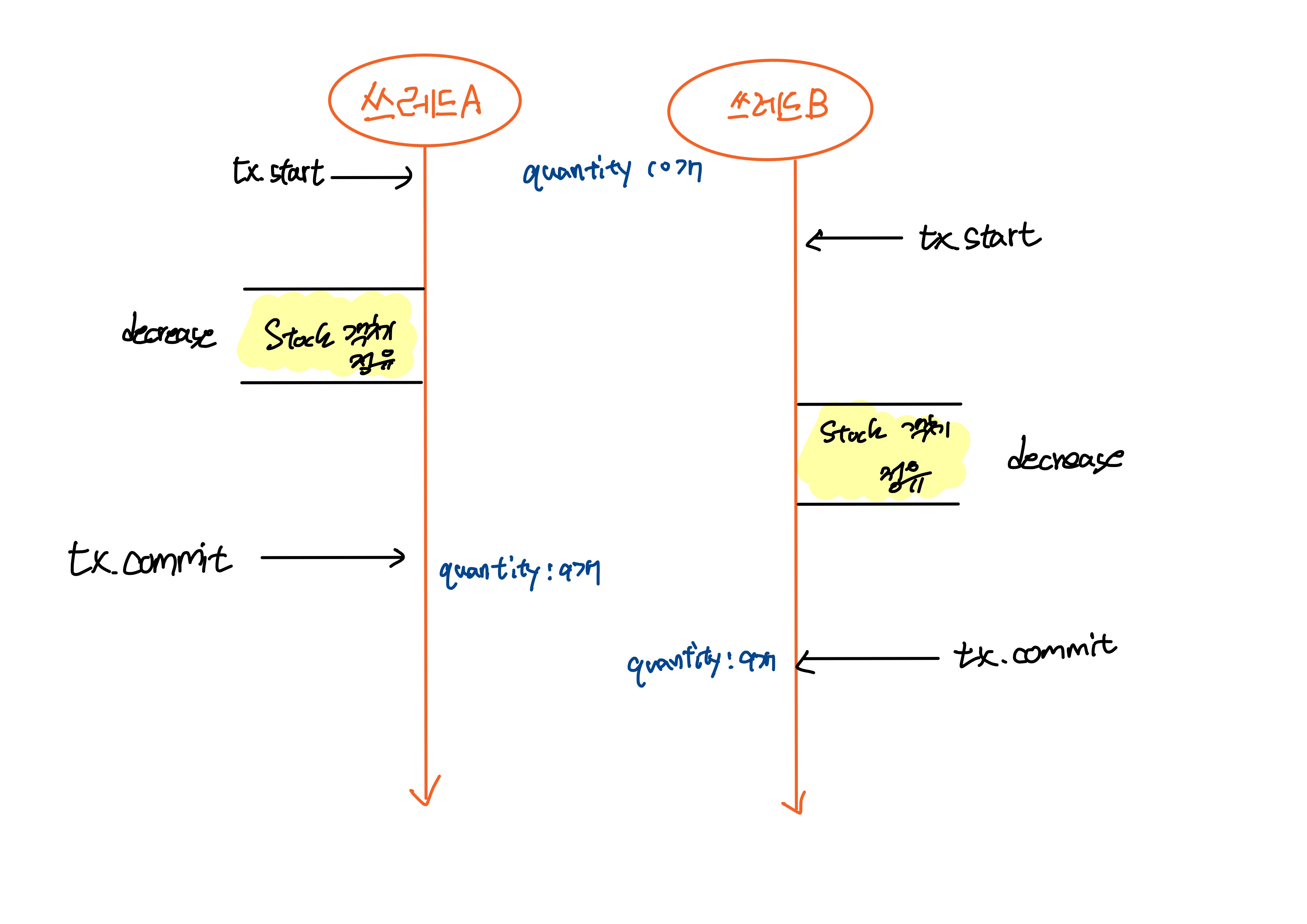
예를 들어 재고관리 시스템에서 재고를 감소시킨다고 생각해보자.
재고는 1개 남았다
만약 두 스레드가 병렬로 작업을 진행하게 되면 어느 한쪽에서 예외가 발생하거나 그래야한다. 하지만 실재로 실행해보면
재고가 0인 경우가 발생할 수 있다.
에에에??왜요???
우리가 생각하기에 병렬로 처리하면 A라는 쓰레드가 처리하고 난후에 B라는 쓰레드가 처리할 것이라고 생각한다.
하지만 실제로 그렇지 않다.

그림을 잘 못그리지만...어째든 저렇다 B가 조회했을때 분명 재고가 1개였지만 B가 업데이트하기전에 A가 먼저 재고를 감소시킴으로써 데이터 정합성 문제가 발생한 것이다.
음 그렇다면 어떻게 해결해야하는데??
오케 대충 이해했어. 그럼 어떻게 해결해??
1. synchronized
- 메소드에 Sychronized를 명시해주서 하나의 스레드만 접근 가능하게 한다.
- 멀티 쓰레드 환경에서 스레드간의 데이터 동기화 시켜주는 자바가 제공하는 키워드다
- 하나의 스레드만 접근가능하기에 다른 스레드는 접근 불가능하다
public synchronized void decrease(int quantity){
stock.decrease(quantity);
}
여기서 궁금한점 왜 @Transactional을 붙이지 않앗을까??
일단 트랜젝션은 데이터베이스의 동일한 엔티티의 접근에 대해서만 동시에 수정되는 것을 방지한다.
그러나 트랜젝션의 begin과 commit 부분은 syncronized의 일부가 아니기때문에 begin을 동시에 한다면 같은 값을 여러 스레드에서 가져가 수정하고 commit전에도 약간의 텀사이에서 여러 스레드가 접근할 수 있다.
따라서 synchronized를 사용한다면 @Transactional을 붙이면 안된다
그러나 자바의 sychronized는 권장하지 않는다. 그 이유는 하나의 프로세스 안에서만 보장되기 때문이다. 즉 서버가 1대이면 상관이 없지만 서버가 2대라면 데이터에 대한 접근을 막을 수 없다.
다시 말해 여러 서버의 각 프로세스의 동시접근 제어만 보장해주는 것이다.
2. DB lock이용
Optimistic lock(낙관적 락)
- 데이터 갱신시 경합이 발생하지 않을 것이라고 봄
- 자원에 락을 거는게 아니라 동시성 문제가 발생하면 그때 처리하는 방식
- 먼저 데이터를 읽은후 update실행할때 현재 내가 읽은 버전이 맞는지 확인하여 업데이트
@Entity
public class Stock{
@Id
@GeneratedValue
private Long id;
private Long quantity;
@Version
private Long version;
}
@Repository
public interface StockRespository extends JpaRepository<Stock,Long>{
@Lock(value=LockModeType.OPTIMISTIC)
@Query("select s form Stock s where s.id=:id")
Stock findByOptimisticLock(Long id);
}
엔티티 필드에 version이라는 필드를 추가해줘야한다.
예를 들어 A,B가 재고를 조회할때 버전 읽고 A가 먼저 update쿼리 수행시 where version=1과 같이 조건절에 버전을 명시하여 쿼리를 날린다.
이후 B가 update쿼리를 수행하는데 where version=1로 했을거지만 이미 A가 업데이틀 쿼리 날리때 버전도 증가시켜서 맞지않아 실패하게 된다.
이 Optimistic lock의 장점은
일단 충돌이 안나다는 가정하에 별도의 락을 잡지 않으므로 성능상 이점이 있을 수 있다.
따라서 동시 업데이트가 거의 없는경우 사용하면 좋다.
다만 B와 같이 업데이를 실패했을때의 재시도 로직을 개발자가 직접 작성해야하고, 충돌이 빈번하게 일어나게 된다면 롤백처리를 해줘야하기대문에 뒤에 설명할 Pessimistic lock이 더 성능이 좋을 수 있다.
Perssimistic lock(비관적 락)
- 동일한 데이터를 동시에 수정할 가능성이 높다고 생각하여 데이터에 lock을 걸어서 정합성을 맞추는 방법
- 한 사용자가 변경시에는 다른 사용자는 레코드 잠금을 릴리즈 할때까지 대기해야함
비관적 락에는 연산종류에 2가지가 있다
- 공유 락
- 다른 트랜젝션이 read연산은 실행가능하지만 write연산은 실행 불가능
- 공유락이 걸린 데이터는 읽기 연산만 실행가능하며, 쓰기 연산은 불가능하다
- 공유락이 걸린 데이터는 다른 트래젝션에서 공유락을 획득할 수 있으나 배타락 획득은 불가능하다
- 배타락
- 해당 트렌젝션만 read연산과 write연산 모두 실행
- 배타락을 획득한 트랜젝션은 읽기,쓰기 연산 모두 실행가능하지만 다른 트랜젝션은 배타락이 걸린 데이터에 읽기 ,쓰기 작업 수행할 수 없다
public interface StockRepository extends JpaRepository<Stock,Long>{
@Lock(value=LockModeType.PESSIMITIC_WRITE)
@Query("select s from Stock s where s.id=:id")
Stock findByPessimisticLock(Long id);
}
Perssimistic lock 읜 장점은 충돌이 번번하게 일어난다면 롤백 횟수를 줄일수 있기때무네 Optimistic Lock보다 성능이 좋을 수 있다.
또한 비관적 락을 통해 데이터를 제어하기때문에 데이터 정합성을 어느정도 보장 가능
다만 데이터 자체의 별도의 락을 잡기때문에 동시성 떨어져 성능저하가 발생가능하고, 읽기만 많이 이루어지는 데이터베이스의 경우 손해가 더 클 수 있고, 서로 자원이 필요한 경우 락이 걸려 데드락이 일어나 갈능성이 있다
아 락 생각해봐야할꺼 엄청 많네..그럼 그냥 큰 단위로 락 걸던가 작은 단위로 여러군데 락 걸을까??
안됭!!!
첫번째 lock경합이 발생하여 특정 세션이 작업을 진행하지 못하고 멈춰설 수 있다.
왜냐면 데이터에 하나의 트랜젝션이 베타락을 걸면 다른 트랜젝션은 접근도 못하기 때문에 트랜젝션이 커밋하고 롤백할때까지 기다려야한다.
-> 해결책: 트랜젝션 짧게 정의 하거나 같은 데이터 갱신에 트랜젝션이 동시에 수행하지 못하게 하거나, lock timeout걸기
두번째 데드락 교착 상태
트랜젝션 A가 한 리소스에 베타락을 걸었고 트랜젝션 B가 다른 리소스에 공유락을 걸었을때
트랜제션 A가 B가 접근한 리소스에 배탁락을 걸고 싶지만 이미 공유락이 걸어져있기 때문에 대기
트랜제션 B도 A가 접근한 리소스에 공유락을 걸고 싶지만 이미 배타락이 걸어져있어 대기
앙??뭐야 무한대기상태야??
-> 해결책 : 트랜젝션 진행방향을 같은 방향으로 처리, 트랜젝션 처리속도 최소화, lock timeout 걸기
Named lock
테이블이나 레코드, 데이터베이스 객체가 아닌 사용자가 지정한 문자열에 대해 락을 획득하고 반납하는 잠금이다.
한 세션이 lock을 획득한다면 다른 세션은 해당 세션이 lock을 해제할때까지 대기해야한다.
다만 단점으로는 lock이 자동으로 해제하지 않기때문에 별도의 명령어로 락을 획득, 반납해야한다.
자자 간단하게 락에 대해서 얘기해봤다. 앞서 말했듯이 여기서는 Redis로 구현한 분산락을 더 자세하게 다룰 것이다. 왜냐면 내 프로젝트에 redis를 통해 분산락을 구현했기 때문 ^^
Redis 를 통한 분산락
앞서 말했듯이 여러 스레드가 접근할 수 있는 공유자원에 대해 경쟁상태가 발생하지 않도록 처리가 필요하다.
분산락은 분산환경에서 상호배제를 구현하여 동시성 문제를 다루기 위한 방법이다. 물론 앞서 얘기한 Mysql named 락으로 데이터 락기능을 활용하여 분산락을 구현할 수 있지만 직접적으로 연관있다고 보기 어렵다.
분산락을 구현한다는 것은 락에 대한 정보를 '어딘가'에 공통적으로 보관하고 있다의 의미다. 여러대의 서버들이 공통으로 어딘가를 바라보며 자신이 임계 영역에 접근할 수 있는 지 확인한다. 이런 분산 환경에서 원자성을 보장할 수 있게된다.
그 '어딘가'라는게 mysql named lock, redis, zookeeper등이 있다.
앞서 얘기했듯이 redis를 통해 예제를 아주아주 간단하게 만들어보겠다
Redis통한 분산락 예제
이 방식은 락을 해제하는 측이 락을 대기하는 프로세스에게 '락 획득 시도를 해도된다'라는 메세지를 발행하는 방식으로 동작한다.
Redisson이라는 라이브러리가 Redis의 메세지 브로커 기능을 활용하여 분산락 메커니즘을 구현하였다. 이 라이브러리는 타임아웃, 일정시간 락 획득못할시 예외발생 의 기능을 설정할 수 있다.
1. build.gradle에 의존성 추가
#redisson
implementation 'org.redisson:redisson-spring-boot-starter:3.18.0'
2. Redisson Config
나같은 경우 비즈니스 로직이 오염되지 않게 분산락 처리 로직을 분리해서 사용하고 싶었다. 찾아보니 AOP를 이용해서 가능했다
@Configuration
public class RedissonConfig {
@Value("${spring.redis.host}")
private String redisHost;
@Value("${spring.redis.port}")
private int redisPort;
private static final String REDISSON_HOST_PREFIX = "redis://";
@Bean
public RedissonClient redissonClient() {
RedissonClient redisson = null;
Config config = new Config();
config.useSingleServer().setAddress(REDISSON_HOST_PREFIX + redisHost + ":" + redisPort);
redisson = Redisson.create(config);
return redisson;
}
}
3. 커스텀 어노테이션
분산락 적용을 커스텀하게 하기 위해 어노테이션을 만들었다
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)
public @interface DistributedLock {
//락 시간단위
TimeUnit timeUnit() default TimeUnit.SECONDS;
//락 획득을 위해 기다리는 시간
long waitTime() default 5L;
//락 획득후 시간 지나면 락을 해제
long leaseTime() default 3L;
}
4. aop만들기
@Aspect
@Component
@RequiredArgsConstructor
@Slf4j
public class DistributedLockAop {
private static final String REDIS_LOCK_PREFIX="LOCK:";
private final RedissonClient redissonClient;
private final AopForTransaction aopForTransaction;
@Around("@annotation(com.project.dogwalker.aop.distribute.DistributedLock)")
public Object lock(final ProceedingJoinPoint joinPoint) throws Throwable{
final MethodSignature signature = (MethodSignature) joinPoint.getSignature();
final Method method = signature.getMethod();
final DistributedLock distributedLock = method.getAnnotation(DistributedLock.class);
String key=REDIS_LOCK_PREFIX+getReserveParameter(joinPoint);
RLock lock=redissonClient.getLock(key);
try{
boolean isLocked=lock.tryLock(distributedLock.waitTime(),distributedLock.leaseTime(),distributedLock.timeUnit());
if(!isLocked){
throw new ReserveNotAvailableException(RESERVE_NOT_AVAILABLE);
}
return aopForTransaction.proceed(joinPoint);
}catch (InterruptedException e){
throw new LockInterruptedException(LOCK_INTERRUPTED_ERROR);
}finally {
try {
lock.unlock();
}catch (IllegalMonitorStateException e){
throw new AlreadyUnLockException(ALREADY_UNLOCK);
}
}
}
private String getReserveParameter(final ProceedingJoinPoint joinPoint) {
final Object[] args = joinPoint.getArgs();
ReserveRequest request=null;
for (Object arg : args) {
if(arg instanceof ReserveRequest){
request=(ReserveRequest) arg;
break;
}
}
if(request==null){
throw new ReserveRequestNotExistException(RESERVE_REQUEST_NOT_EXIST);
}
return request.getWalkerId()+""+request.getServiceDate();
}
}
위의 코드는 내 프로젝트에 적용되는 코드이다
일단 @DistributedLock이 적용된 메서드가 있다면
락의 이름은 내가 커스텀하게 만들어서 Rlock인스턴스를 가져온다.
어노테이션에 정의된 waittime,leasetime을 설정하여 락을 획득한다.
어노테이션이 붙은 메서드를 실행하낟
종료시 무조건 락을 해제한다
근데 저기서 AopForTransaction은 뭐야??
@Component
public class AopForTransaction {
@Transactional(propagation = Propagation.REQUIRES_NEW)
public Object proceed(final ProceedingJoinPoint joinPoint) throws Throwable{
return joinPoint.proceed();
}
}
@DistributedLock이 선언된 메서드는 해당 전파 옵션을 통해 부모 트랜젝션의 유무에 관계없이 별도의 트랜젝션으로 동작하게끔 설정해따.
그리고 반드시 트랜젝션 커밋이후에 락이 해제되게끔 하였다.
그 이후는 결국에 동시성환경에서의 데이터 정합성 보장을 위해서다.
만약에 락의 해제시점이 커밋 시점보다 빠르다면 다른 client가 커밋이 반영되지 않은 상태의 데이터를 바탕으로 데이터를 다룬다. 결과적으로 정합성의 문제가 생기는 것이다
오케 이해했어. 근데 왜 redis를 이용했어?? lettuce나 mysql이용할 수 도 있잖아??
일단 lettuce를 이용하지 않은 이유는
첫번째 분산락 사용을 위해 setnx,setex을 이용해 직접 분산락을 구현해야한다. retry,timeout과 같은 기능도 개발자가 구현해줘야한다.
이에비해 redissond은 lock interface를 제공하여 락에 대한 타임아웃과 같은 설정을 제공한다.
두번째 서버 부하
lettuce의 경우 분산락 구현지 setnx,setex명령얼르 통해서 지속적으로 redis에게 "저기 락 해제됬니..?" 를 요청하는 스핀락 방식으로 동작한다. 요청이 많아지만 redis가 받는 부하가 커진다
그럼 Mysql은...?
나의 경우 mysql이 락에 관련된 요청으로 인해 부하를 주고 싶지 않는 마음이 컸다.
뿐만 아니라 mysql 분산락 경우 비지니스 로직에 사용하는 db connection pool과 lock획득을 위한 db connection pool을 분리하는 작업이 필요하다고 한다.
또한 어떠한 작업이 오래걸린다면 작업시간만큼 잠금을 소유하게 된다. 이로인해 작업들은 타임아웃 실패하게되는 부분들이 존재한다
redisson의경우 leasetime이라는 기능때문에 락 획득시간이 만료되면 다른작언들이 해당 락을 요청할 수 있다. mysql경우 leasetime에 대해 명시적으로 지정하는 기능이 없다고 한다. 즉 직접 구현해야하는데...과연 내가 할 수 있을려나...
다만 redisson이 무조건적으로 좋은게 아니다. 다 개발 상황마다 다르다. 만약 redis서버를 사용하지 않고있는 서비스라면 이 분산락 하나만을 위해 redis서버를 구축해야한다. 뭐 인프라 구축비용뿐만 아니라 유지보수에도 비용이 발생한다. 이런 경우에는 Mysql을 사용하는게 나을것같다.
아 생각보다 이 락에 대해서 알아보고 쓰다보니 한 3-4시간 걸린것같다. 하나 이해가 안되면 글을 못쓰는 사람이라...하하하하하
밑 url에 lettuce를 구현한것과 Mysql로 구현한 것들이 있다. 필요하다면 참고하길...
https://helloworld.kurly.com/blog/distributed-redisson-lock/
https://hudi.blog/distributed-lock-with-redis/
https://techblog.woowahan.com/2631/